Under Review
Contrastive Action-Image Pre‑training
for Visuomotor Control
TL;DR. Robot data is too scarce for large-scale pre-training. CAIP instead learns action-centric visual features from 32,041 hours of egocentric human video by treating 3D hand poses as a proxy for end-effector actions, aligning vision and action through a contrastive objective. With only 88 hours of robot data, CAIP reaches a 76% average success rate on real-world dexterous manipulation, over 30 points above the strongest vision-encoder baseline.
Motivation
Why action-centric, egocentric pre-training?
Visual perception underpins robotic manipulation, yet the encoders that power modern policies were never designed for physical interaction. Image-text models like CLIP and SigLIP capture semantics; self-distilled models like DINOv2 capture fine-grained spatial details. But neither sees manipulation environments during training, so their representations lack any action-centric structure.
The most direct fix, pre-training on robot trajectories, runs into a wall: robot data is orders of magnitude smaller than internet-scale corpora. Egocentric human video, by contrast, is abundant and captures the same first-person viewpoint a head-mounted robot camera observes, with naturally co-occurring hand motion. CAIP turns human hand poses into a proxy for end-effector actions, unlocking action-conditioned pre-training at scale.
Method
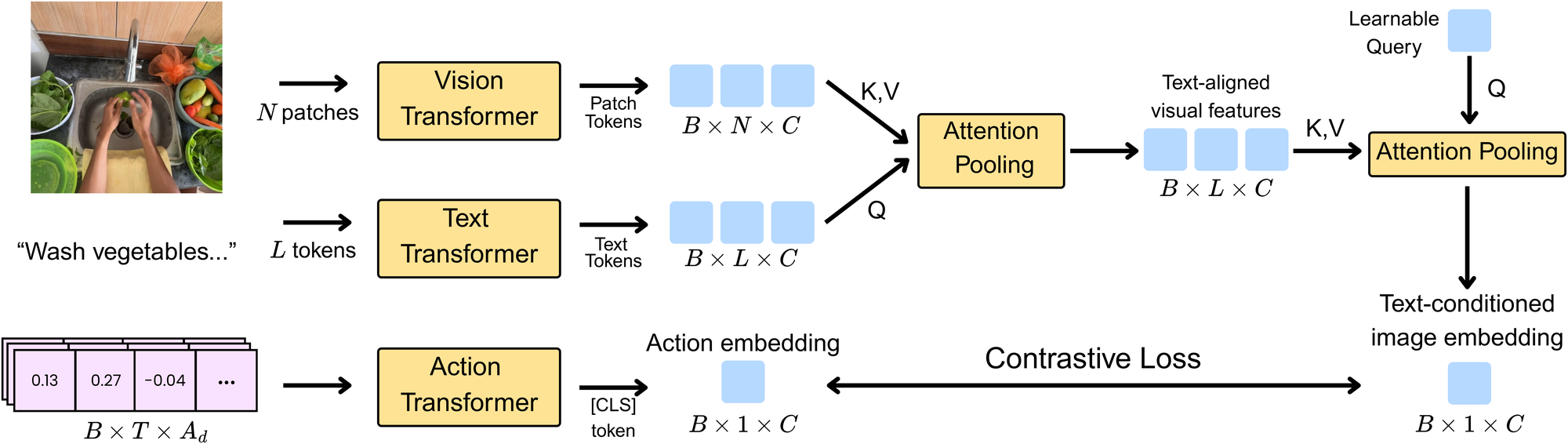
Aligning vision and action by contrast
CAIP uses three encoders: vision, language, and
action. A ViT-L/16 image tower and a 24-layer text tower (initialized from SigLIP 2)
produce patch and token features; a lightweight 4-layer action transformer encodes a chunk of future
hand motion into a single embedding via a [CLS] token. We attention-pool patch tokens
using text tokens as queries, then pool again with a learnable query to form a
text-conditioned image embedding. This embedding and the action embedding are
aligned with a SigLIP-style sigmoid contrastive loss.
Hand poses as actions
Each hand is represented by 21 keypoints as SE(3) transforms (MANO convention). Action chunks emulate end-effector delta control over T = 64 steps, roughly two seconds of future motion at 30 Hz, aligning naturally with robot action spaces.
Scale from human video
Training spans ~1,000 h of lab data (with wrist views), ~31,000 h of in-the-wild egocentric video, and ~88 h of tabletop humanoid data for embodiment diversity, far beyond what robot datasets alone can offer.
A modular, frozen backbone
The pre-trained encoder transfers to a closed-loop policy: a decoder-only transformer (Qwen3.5-0.8B) trained from scratch with a flow-matching action head, on top of frozen CAIP features.
Experiments
Results
Across six real-world dexterous tasks on a Dexmate Vega bimanual robot with two 22-DoF Sharpa Wave hands (12 trials each), CAIP reaches the highest average success rate, 76.0%, over 30 points above the strongest baseline, and tops 5 of 6 tasks. Baselines are competitive on some tasks but collapse on others; CAIP stays strong across the board.
| Method | Fold Shorts | Pour | Pick Fruits | Dispense Soap | Turn On Lamp | Pull Tissue | Avg. |
|---|---|---|---|---|---|---|---|
| R3M | 14.6 | 12.5 | 2.1 | 29.2 | 8.3 | 37.5 | 17.4 |
| Qwen3.5 ViT | 27.1 | 22.9 | 60.4 | 72.9 | 8.3 | 12.5 | 34.0 |
| VideoMAE | 22.9 | 52.1 | 0.0 | 37.5 | 25.0 | 18.8 | 26.0 |
| VC-1 | 18.8 | 56.3 | 0.0 | 62.5 | 0.0 | 22.9 | 26.7 |
| MVP | 54.2 | 62.5 | 2.1 | 93.8 | 8.3 | 31.3 | 42.0 |
| DINOv2 | 22.9 | 81.3 | 52.1 | 50.0 | 25.0 | 20.8 | 42.0 |
| SigLIP | 12.5 | 70.8 | 37.5 | 83.3 | 25.0 | 25.0 | 42.4 |
| SigLIP 2 | 4.2 | 35.4 | 52.1 | 93.8 | 50.0 | 25.0 | 43.4 |
| CAIP (Ours) | 68.8 | 83.3 | 56.3 | 100.0 | 75.0 | 72.9 | 76.0 |
Success rates (%) over 12 trials per task. Bold = best, underline = second best.
Policy rollouts
Closed-loop rollouts of CAIP-conditioned policies across the six evaluation tasks on the Dexmate Vega with Sharpa Wave dexterous hands. All videos play at 1× (real-time) speed.
To test transfer beyond the embodiment and domain CAIP was trained for, we evaluate on the ManiSkill2 Franka benchmark: a single 7-DoF arm with a parallel-jaw gripper on tabletop tasks. This is a large shift from CAIP’s egocentric, dexterous, bimanual pre-training: different embodiment, action space, and visual domain (simulation vs. real video). We keep the same protocol: frozen encoder, policy trained from scratch on 200 demonstrations per task, 12 trials each. Despite the domain gap, CAIP again achieves the highest average success rate (77.8%), ahead of SigLIP 2 (72.2%) and DINOv2 (69.4%).
| Encoder | Lift Peg | Stack Cubes | Push Cube | Avg. |
|---|---|---|---|---|
| VC-1 | 16.7 | 0.0 | 100.0 | 36.1 |
| R3M | 25.0 | 16.7 | 91.7 | 44.4 |
| MVP | 33.3 | 0.0 | 100.0 | 44.4 |
| DINOv2 | 58.3 | 50.0 | 100.0 | 69.4 |
| SigLIP 2 | 58.3 | 58.3 | 100.0 | 72.2 |
| CAIP (Ours) | 75.0 | 58.3 | 100.0 | 77.8 |
ManiSkill2 Franka success rates (%) over 12 trials per task. Bold = best, underline = second best.
Policies are trained only under standard conditions, so any change in success rate reflects the visual representation’s sensitivity to perturbation. CAIP is the most robust encoder under every lighting and distractor perturbation we test.
Lighting variation
| Encoder | Turn on Lamp | Dispense Soap | Fold Shorts | Average | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Orig. | Light | Dark | Orig. | Light | Dark | Orig. | Light | Dark | Orig. | Light | Dark | |
| Qwen3.5 ViT | 8.3 | 0.0 | 16.7 | 72.9 | 58.3 | 56.3 | 27.1 | 8.3 | 0.0 | 36.1 | 22.2 | 24.3 |
| MVP | 8.3 | 0.0 | 8.3 | 93.8 | 8.3 | 39.6 | 54.2 | 8.3 | 4.2 | 52.1 | 5.6 | 17.4 |
| CAIP (Ours) | 75.0 | 25.0 | 33.3 | 100.0 | 93.8 | 75.0 | 68.8 | 35.4 | 20.8 | 81.3 | 51.4 | 43.1 |
Distractor objects
| Encoder | Turn on Lamp | Dispense Soap | Fold Shorts | Average | ||||
|---|---|---|---|---|---|---|---|---|
| Orig. | 2 Distr. | Orig. | 2 Distr. | Orig. | 2 Distr. | Orig. | 2 Distr. | |
| Qwen3.5 ViT | 8.3 | 8.3 | 72.9 | 60.4 | 27.1 | 16.7 | 36.1 | 28.5 |
| MVP | 8.3 | 0.0 | 93.8 | 12.5 | 54.2 | 16.7 | 52.1 | 9.7 |
| CAIP (Ours) | 75.0 | 33.0 | 100.0 | 85.4 | 68.8 | 39.6 | 81.3 | 52.8 |
Success rates (%). Policies trained only under original conditions. Bold = best.


Analysis
Each encoder’s regions of focus
Side-by-side rollouts compare CAIP against DINOv2 and SigLIP 2 on the same task. Each encoder is shown from a side view and the robot’s head camera, with a saliency map computed using its native query mechanism: CAIP’s text-conditioned cross-attention pool, SigLIP’s learned-probe pooling, and DINOv2’s per-image PCA of patch features. CAIP concentrates on the hands and manipulated objects, while SigLIP 2 scatters across the background and DINOv2 segments by appearance but is instruction-unaware. All videos play at 1× (real-time) speed.
Turn On Lamp
Pour
Pull Tissue
Ablations
Scaling the vision encoder
We ablate CAIP along two axes: encoder capacity and pre-training data scale, under identical data, training, and optimization settings.
Capacity scaling
Scaling the backbone across ViT-B/16, ViT-L/16, and ViT-SO400M/16 improves performance consistently. The largest jump is ViT-B → ViT-L (+33 points average), driven by the harder tasks. ViT-SO400M adds only a few more points at a large compute cost, so we adopt ViT-L as the primary encoder.
| Task | ViT-B/16 | ViT-L/16 | ViT-SO400M/16 |
|---|---|---|---|
| Turn On Lamp | 16.7 | 75.0 | 83.3 |
| Fold Shorts | 54.2 | 68.8 | 79.2 |
| Dispense Soap | 72.9 | 100.0 | 100.0 |
| Average | 47.9 | 81.3 | 87.5 |
Downstream success rates (%). Bold = best per row. ViT-L (used in all main experiments) shown for reference.
Data scaling
Holding the encoder fixed at ViT-L/16 and varying the fraction of pre-training data, performance improves monotonically, from 50.0% at 20% of the data to 77.8% at full scale, with no sign of saturation. CAIP would likely keep benefiting from more egocentric data. Evaluated on the ManiSkill2 Franka tasks.
| Pre-training data | Lift Peg | Stack Cubes | Push Cube | Avg. |
|---|---|---|---|---|
| 20% | 58.3 | 25.0 | 66.7 | 50.0 |
| 50% | 66.7 | 33.3 | 83.3 | 61.1 |
| 100% | 75.0 | 58.3 | 100.0 | 77.8 |
ManiSkill2 Franka success rates (%) over 12 trials per task. Bold = best per column.
Get started
Using the encoder
CAIP loads as a standard 🤗 Transformers
model. Install transformers, torch, and pillow, then encode an
image and instruction into text-conditioned visual features.
from transformers import AutoModel, AutoProcessor
from PIL import Image
import torch
REPO = "yuvansharma/caip-vitl256"
model = AutoModel.from_pretrained(REPO, trust_remote_code=True).eval()
processor = AutoProcessor.from_pretrained(REPO, trust_remote_code=True)
image = Image.open("example.png").convert("RGB")
inputs = processor(images=image, text="pick up the red cup", return_tensors="pt")
with torch.no_grad():
out = model(**inputs)
# out.image_pooled [B, 1024] text-conditioned pooled image embedding
# out.patch_features [B, 256, 1024] patch tokens
# out.text_tokens [B, 64, 1024] text token embeddings
# out.text_pooled [B, 1024] pooled text embeddingCitation
BibTeX
@misc{sharma2026contrastiveactionimagepretrainingvisuomotor,
title={Contrastive Action-Image Pre-training for Visuomotor Control},
author={Yuvan Sharma and Dantong Niu and Anirudh Pai and Zekai Wang and Zhuoyang Liu and Baifeng Shi and Stefano Saravalle and Boning Shao and Ruijie Zheng and Jing Wang and Konstantinos Kallidromitis and Yusuke Kato and Fabio Galasso and Yuke Zhu and Danfei Xu and Linxi "Jim" Fan and Jitendra Malik and Trevor Darrell and Roei Herzig},
year={2026},
eprint={2606.17256},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2606.17256},
}